Claude Opus 5 被曝今晚发布,Fable 5 的水平,腰斩的价格
Claude Opus 5 被曝今晚发布,Fable 5 的水平,腰斩的价格大家还没等来DeepSeek V4的发布消息,Anthropic家Claude Opus 5今夜即将推出的消息,已经先把全网开发者的热情点燃了。一句"性能强得超乎想象,各大平台正陆续上线"的传闻,将全网的目光再次聚焦在Anthropic上。
来自主题: AI资讯
8902 点击 2026-07-24 00:24
 搜索
搜索
大家还没等来DeepSeek V4的发布消息,Anthropic家Claude Opus 5今夜即将推出的消息,已经先把全网开发者的热情点燃了。一句"性能强得超乎想象,各大平台正陆续上线"的传闻,将全网的目光再次聚焦在Anthropic上。

一夜之间,Tokenmaxxing成为硅谷热议话题!

全网等了快三个月!DeepSeek V4正式版,可能最早明日发布,最迟不过这几天。目前,一部分人已提前拿到了DeepSeek V4(GA)灰度测试的权限。一共有两个版本:DeepSeek V4 Flash,DeepSeek V4 Pro。

最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。

今天,据英国《金融时报》报道,两位知情人士透露,DeepSeek本周开始与新的投资者展开初步接触,讨论开启新一轮融资,投前估值约为710亿美元(约合人民币4813.9亿元),较其首轮融资估值提升约37%。不过,新一轮融资的具体细节尚未最终确定。

浪潮信息宣布,元脑SD200超节点AI服务器率先完成主流领先开源大模型Kimi K2.6、DeepSeek V4、GLM 5.2、MiniMax M3等的高性能优化,并在Kimi K2.6万亿参数大模型上实现Token生成时间快达4.77ms,为Agent场景应用的高效运行提供强大算力支撑。

月之暗面旗下新一代大模型 Kimi K3 已由员工在 X 上确认,将于本月内发布。据多方信源,K3 的参数规模将达到 2.5 万亿——这一数字不仅超越了 DeepSeek V4 Pro 的 1.6 万亿,也成为当前已公开参数规模最大的国产模型。
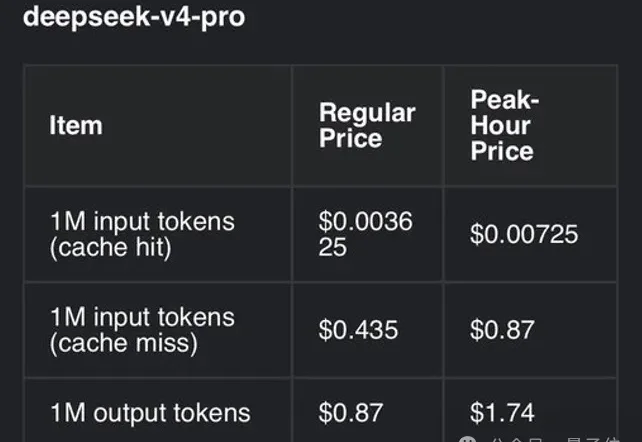
也是神奇,价格屠夫DeepSeek,破天荒要涨价了!

刚刚,DeepSeek V4 进行了一次更新。新推出了投机解码(Speculative Decoding)框架 DSpark,并同步开源了支撑该版本的全栈推测性解码框架 DeepSpec。DeepSeek-V4-Pro-DSpark 并非全新架构模型,而是在 DeepSeek-V4-Pro 基础上引入了推测性解码模块。此次更新的重点在于工程落地,而非模型能力本身的迭代。
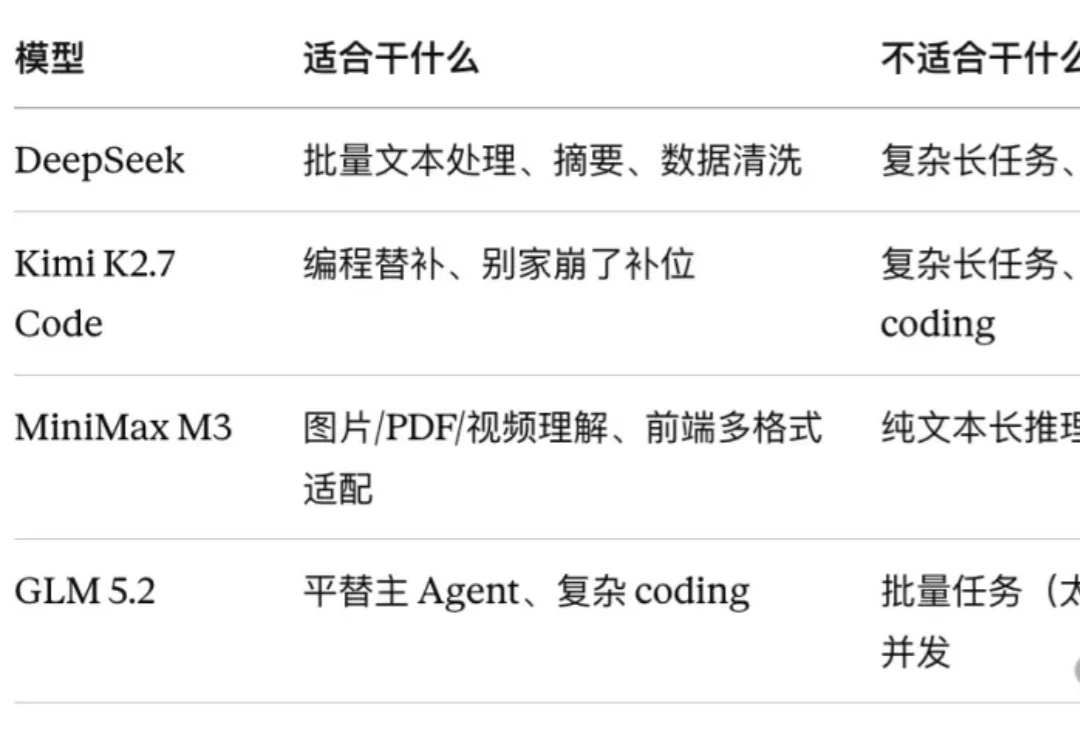
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。